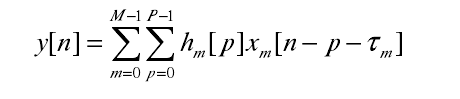深度神经网络的基本原理
在 DNN 声学模型应用于语音识别中,较之前的浅层神经网络参数初始化的方法略有不同。早期的神经网络参数的初始化主要是随机进行初始化的,而 DNN 参数的初始化值主要是利用大量的语音数据输入生成一个具有多个隐含层的生成性模型。DNN 的基本框架图 2.3 所示。
图 2.3 表示语音数据经过 DNN 的输入层,得到的特征参数再利用深度信念网络 [39-41]进行逼近,这种训练过程称为预训练过程。在网络结构的最后一个隐含层加入 softmax 函数,从而得到输出层值,然后用初始化后的网络权重利用反向传播算法(Back Propagation,BP)对网络的权重精确的微调(fine-tuning),以便得到准确的网络权重。DBN 是通过多个受限玻尔兹曼机制的神经单元构建而成的。
基于优化阵列参数的远距离语音识别方法
远距离语音识别的方法一般是为了提高语音信号质量,也就是针对信号增强和提高信噪比这两方面。这些方法大多数情况下关注的是能够通过麦克风阵列的输出端得到一个最佳的语音信号波形,因此这些方法依据的是不同的信号准则对远距离语音进行处理,例如最大化信噪比原则和来波方向最小化失真准则。然而,在这些准则下,并没有改善对语音识别来说至关重要的特征参数,进而阵列处理后的语音信号并没有明显改善。
由于语音识别不仅是信号处理领域,同样属于模式识别领域。语音识别的基本过程是把采集到的语音波形变换成特征参数向量,然后用语音识别器把特征参数向量和统计模型一一进行匹配,得到了使正确分类的状态序列似然概率最大,最终通过状态序列来得到识别结果。
因此,麦克风阵列处理问题总结为寻找使最大化正确假设概率的阵列参数。论文是在滤波求和波束形成算法中解决该问题的。因此,该方法称之为最大化似然概率波束形成,也就是优化阵列参数的方法[26,45]。
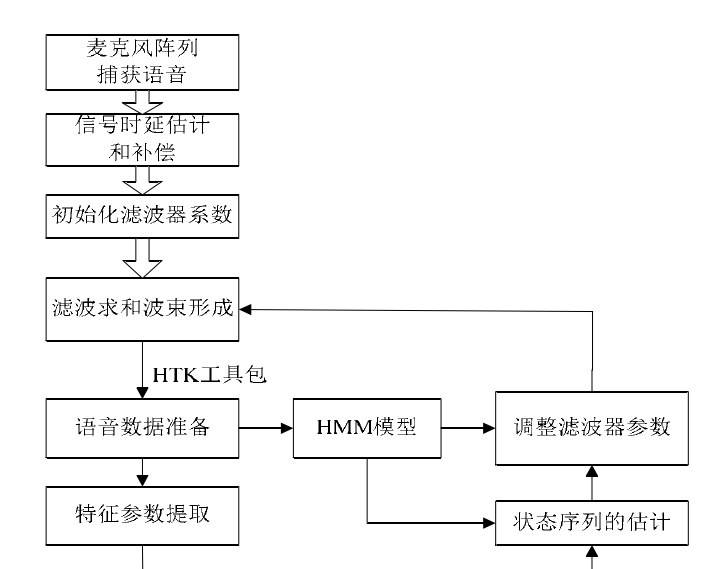

首先对阵列采集到含噪的语音信号信息,进行多通道的语音信号的时延估计并对其时延补偿,然后经过滤波-求和波束形成处理,把多路信号变为一路降低噪声的纯净语音信号,滤波器系数代表了阵列参数。当训练的过程中,由语音识别器输出的假设录音反馈回来进一步调整阵列参数向量,使得阵列参数向量得到进一步优化,产生的最大化特征参数,由最大化特征参数最后得到最大化正确假设的似然概率。
波束形成[48-49]的基本思想是指在麦克风阵列采集语音信号时,由于信号经过不同的路径到达麦克风阵列,导致采集到的语音信号有延迟,因此为补偿各个麦克风得到信号的时间延迟,进行时间上的延迟补偿,能够使多通道的信号同步的聚集在所期望的方向上,因此某一特定方向的期望信号强度被加强,相反的,那些不期望的信号或者噪声被抑制或者消除,最终将得到的所有同步信号进行加权求和。
这个处理过程用数学公式表示为

那么由延时求和波束形成算法延伸到滤波求和波束形成的算法[50-51]。表达式为